
Sztuczna Inteligencja (SI) przenika kolejne sfery naszego życia. Dla wielu jest początkiem nowej ery, dla innych puszką Pandory. Istotnie, doceniając wszelkie zalety SI, nie można pozostawić bez odpowiedzi kwestii zagrożeń i wyzwań, jakie się z nią wiążą.
Temat ten został podjęty przez Komisję UE w obszernym raporcie „Algorithmic discrimination in Europe: Challenges and opportunities for gender equality and non-discrimination law” autorstwa Janneke Gerards (Utrecht University) i Raphaële Xenidis (University of Edinburgh and University of Copenhagen) z 2020 roku. Problemy w nim podjęte zostaną poruszone poniżej, a także w kolejnych artykułach, które również zostaną opublikowane na tym blogu. Celem tego artykułu jest przybliżenie zasad na jakich opiera się praca algorytmów.
Algorytmy można zdefiniować jako zbiór komputerowych instrukcji dla serii wprowadzanych danych, co daje szerokie spektrum możliwości. Działając w oparciu o te właśnie dane, algorytmy mogą wygenerować kluczowy dla nas tzw. output, wskazujący zasadność decyzji albo szacujący prawdopodobieństwo wystąpienia pewnych zjawisk. Przykładem takich jakościowych wyników może być komunikat zwrotny o przyznaniu danej osobie świadczenia socjalnego, komunikat dotyczący mandatu w przypadku stwierdzenia przekroczenia prędkości czy też informacja o stwierdzeniu wzmożonej przestępczości w danym rejonie. Natomiast przykładami ilościowych wyników byłoby określenie wielkości przyznanego świadczenia socjalnego oraz możliwe modyfikacje jego wartości w odniesieniu do przedłużenia lub skrócenia czasu pracy konkretnej osoby, a nawet całej grupy pracowników danego zakładu pracy. Inne przykłady aplikacji takich wyników można znaleźć w artykułach . Tego typu informacje zwrotne, uzyskiwane w kilka sekund od wprowadzenia danych, nie pozostają tylko kwestią teorii, ale mają istotne realne znaczenie praktyczne.
Jednak aby algorytmy spełniały te wszystkie funkcje, konieczna jest ich uprzednia weryfikacja, aby wykluczyć ryzyko błędnych i niedopracowanych algorytmów, które mogą rodzić niepożądane wyniki, widocznych od razu, a czasem zidentyfikowanie takich problemów jest wynikiem przypadku po miesiącach jego używania.
Do takich niepokojących zjawisk przejawiających wadliwość funkcjonowania algorytmu należy wyraźna tendencyjność ich wyników pracy, która skłania do pytania, co poszło nie tak?
Aby odpowiedzieć, nie wystarczy jedynie dostrzeżenie faktu, że dyskryminować mogą nie tylko ludzie, ale również algorytmy. Konieczne jest zagłębienie się w metodykę, według której działają.
Systemy regułowe (Rule-based alghoritms)
W pewnym uproszczeniu można stwierdzić, że algorytmy przeprowadzają procesy myślowe zgodnie ze schematem rozumowania ‘jeśli x, to y’.
Wyobraźmy sobie przepis prawny: jazda z prędkością przekraczającą 200 km/h na drodze ekspresowej jest zabroniona, a naruszenie tej zasady skutkuje nałożeniem mandatu. Wynika z tego, że jeżeli ktoś przekroczy dozwoloną prędkość 200 km/h na ekspresówce, będzie musiał zapłacić mandat.
W przypadkach wymagających większych zabiegów myślowych ilość logicznych sub-reguł i zmiennych odpowiednio się rozrasta (w dalszym etapie naszego przykładu możemy określić zakresy finansowe grożących kar i dodatkowe wykroczenia w postaci nadużycia alkoholu). Proces decyzyjny ulega podziałowi na mniejsze moduły działające zgodnie z regułą wyjściową (zob. mechanizm pracy przykładowego algorytmu opartego o systemy regułowe na drzewie decyzyjnym poniżej).
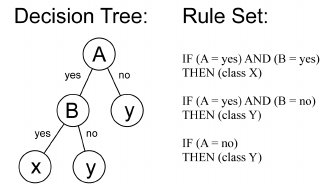
Algorytmy komputerowe zaprojektowane według zasady ‘jeśli x, to y’ tworzą przewidywalne systemy knowledge-based, są one bowiem oparte o stałe reguły i dokładnie określony zestaw zmiennych. Stają się one szybszą i wydajniejszą alternatywą w porównaniu z procesem decyzyjnym człowieka. Wymaga jednak podkreślenia, że warunkiem sprawnego działania takiego algorytmu rule-based jest dostarczenie mu precyzyjnych, jednoznacznych zmiennych, które można by ująć w myśl reguły ‘jeśli x, to y’.
Algorytmy uczenia maszynowego
W porównaniu do algorytmów rule-based, algorytmy uczenia maszynowego są „inteligentniejsze”, gdyż wykazują się zdolnością do uczenia. Potrafią się samodzielnie zaadaptować, rozwijać i doskonalić, aby optymalizować swoje wyniki uzyskane na podstawie analizy jakichkolwiek danych wejściowych bez wyraźnego zaprogramowania w tym celu. Cechuje je dynamiczne działanie, gdyż w przeciwieństwie do algorytmów rule-based reguły, którymi się kierują zmieniają się w zależności od typu danych wejściowych. Korzystają z różnych technik analitycznych (określonych poniżej), które umożliwiają im ustalanie korelacji i wzorców w szczególnie obszernych bazach danych.
Za pomocą technik klasyfikacyjnych, algorytm może posiąść umiejętność rozpoznawania kategorii odpowiadających poszczególnym danym na podstawie wcześniej zdefiniowanych klas. to osiągnąć, algorytm uczy się na podstawie wyselekcjonowanych uprzednio przez człowieka wiadomości noszących znamiona spamu (zawierających typowe dla spamu sformułowania).
Następnie – po procesie katalogowania – algorytm uczy się rozpoznawać wiadomości ze spamem, kierując się cechami wspólnymi, które je wyróżniają, np. charakterystycznymi zwrotami. Stąd, w przychodzących do nas uciążliwych wiadomościach mailowych, ciągle zmieniają się tytuły maili i nadawcy.
Techniki grupowania mogą okazać się przydatne przy wykrywaniu fałszywych raportów podatkowych, o ile zdradzi je jakaś odmienność względem tych prawdziwych. Dzięki tej technice algorytm może nauczyć się zdolności rozpoznawania zbieżności, podobieństw i korelacji wśród najróżniejszych danych. Jednak oprócz możliwości tworzenia swoistych klastrów sytuacji, wydarzeń lub osób o porównywalnych cechach (np. zainteresowaniach, preferencjach), algorytm może również (albo przede wszystkim!) wyłapać anomalie.
Techniki regresyjne świetnie sprawdzą się w przypadku sektora bankowego, gdyż dzięki wykształceniu w algorytmach biegłości w szacowaniu prawdopodobieństwa, będą one zdolne kalkulować poziom ryzyka kredytowego opierając się na porównaniu danych osobistych z tymi dotyczącymi historii kredytowej czy sytuacji życiowej.
Z kolei przedsiębiorcy, w szczególności w branży e-commerce, wykażą prawdopodobnie największe zainteresowanie technikami asocjacyjnymi. Używając ich, algorytm zdolności dostrzegania ścisłych korelacji między danymi ukierunkowanymi na przyszłość. Na przykład, algorytm będzie mógł dostrzec bliską zależność pomiędzy zakupem smartfona i pasującego na niego etui albo pomiędzy oglądaniem serialu X, a następnie serialu Y. Takie korelacje tworzą tzw. „zasady stowarzyszenia”, które mogą być następnie wykorzystane do sugerowania klientom dodatkowego zakupu, ustalania cen, personalizacji informacji czy w celach praktyki zwanej behavioural targeting.
Reasumując, zastosowanie każdej z powyższych technik przynosi pojedyncze korzyści, jednak najbardziej optymalne rezultaty są możliwe dzięki sumarycznemu ich wykorzystaniu. Na przykład, dzięki kombinacji techniki grupowania i asocjacyjnej można zidentyfikować profil zawodowy lub nawet stan cywilny danej osoby. Poprzez następcze wdrożenie technik regresyjnych, algorytm może przewidywać inne preferencje tej osoby, np. skłonności do używek. Na koniec, należy szczególnie podkreślić niekwestionowaną przydatność algorytmów w zakresie przewidywania ludzkich zachowań lub wystąpienia konsekwencji zdarzeń.
Szereg kolejnych zagadnień zostanie omówionych w drugim artykule z tej serii. Aby dowiedzieć się więcej, m. in. o uczeniu wzmocnionym, czy konkretnych przyczynach dyskryminacji przez algorytmy.

